


The DataStory is back, after time away working on a bigger writing project—to be announced.
Last week the FTC released a report on social media companies’ misuse of data. It took twenty years to identify Big Tech’s wrongdoings; but Big AI--OpenAI and others--are misusing data… specifically intellectual property… out in the open, and right now.

What the Times Saw
The New York Times blew the whistle on OpenAI with a complaint they filed in December 2023. The Times’s complaint reveals how a large language model (LLM) like Chat GPT uses other people’s data for training.
Remember that these models are like any other models--they have inputs, they process the inputs with math, they have outputs.
The input for a LLM is language. Language that has been transformed into tokens--which basically means, words that have been converted to numbers.

For ChatGPT--as you can see from this table, an exhibit from the Times complaint--the first source of tokens is a database called Common Crawl. Common Crawl is “a “copy of the Internet,’” according to the complaint, “made available by an eponymous 501(c)(3) organization run by wealthy venture capital investors.”
According to the table, Common Crawl contributed 410 billion tokens to GPT. At a ratio of 0.8 words per token, let’s call it 350 billion words.
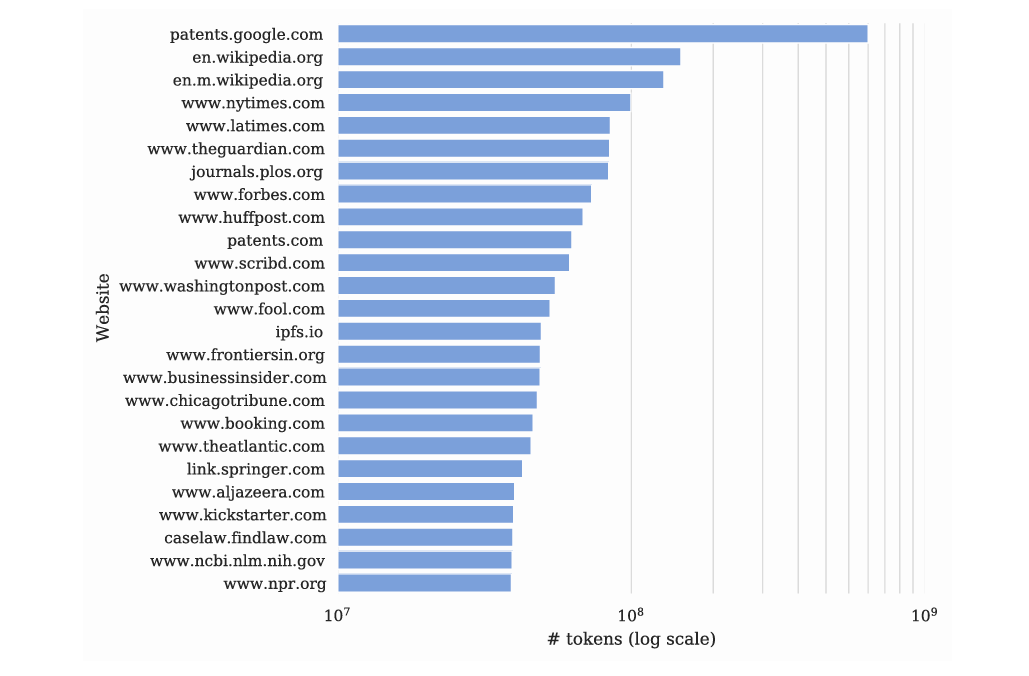
The Times complaint further splits that out. It lists all the websites within Common Crawl. This includes a Google patent database (patents are government documents, and hence not copyright-able)... Wikipedia… and then a lot of newspapers and magazines. You’ll notice that The New York Times is the fourth largest overall contributor to the Common Crawl database, contributing 10^8, or 100 million tokens. Let’s call it, 80 million words. That’s a lot of articles.
In other words, OpenAI trains ChatGPT on a colossal data set that belongs to someone else. The equivalent of copying off someone else’s test in high school.
Also known as cheating.
The Underbelly
After The Times complaint, OpenAI seems to have gotten religion for cutting deals. Conde Nast, TIME, The Atlantic, Vox Media, NewsCorp, and the FT, have all cut deals with OpenAI. Now, it would appear, many important training tokens are paid for.
If this were the extent of it, it all might be pointed towards a happy ending where OpenAI and the New York Times settle on a fair price for their content, and OpenAI still makes a margin on it, the way a cookie manufacturer clears a margin on the price of flour and sugar.
But there is an underbelly.
Every second of every day, the major AI companies also employ bots, or crawlers… which I can’t help but think of as foraging insects… to scour the internet and gather information. Bring that information back to the ant hill… and use it. So if your writing appears on any website--like, say, Substack, or LinkedIn--it will be subject to crawling.
According to the OpenAI website:
OpenAI uses web crawlers (“robots”) and user agents to perform actions for its products, either automatically or triggered by user request.
For instance,
GPTBot is used to crawl content that may be used in training our generative AI foundation models.
The actions of these bots is determined by an ecosystem referred to as Robots.txt, or the Robots Exclusion Protocol.
You might not have heard of it. Tech people have. It’s a protocol established in the 90s for steering search engine web crawlers; “to indicate to visiting web crawlers and other web robots which portions of the website they are allowed to visit.”
Now that same approach is being repurposed to block or admit AI web crawlers.
Bot vs. Bot
This, I suppose, would be fair, if a few things were true.
First, if everyone understood that unlike search engines, these bots are not providing a service (that is, helping your content to be discovered). They are making off with, and reselling, your content without payment.
Second, if the bot owners were playing fair--for instance, by keeping their bots names consistent, so that sites could block them.
But these conditions are not being met. According to a research paper, only 26% of sites block OpenAI, only 13% block Common Crawl (which as we learned, feeds OpenAI), and only 4% block Meta.
Also, website 404 Media reports that bots employed by Anthropic have changed the names of their bots to circumvent the robots.txt protocols. Their old bots, CLAUDE-WEB and ANTHROPIC-AI were switched out for a new bot called CLAUDEWEB, which would circumvent settings blocking the old.

With each visit, the foraging insect makes off with intellectual property. If it can’t get in the door, it will get in the window or the crack in the floorboard. And it is literally happening right now, millions of times a day.
(Cue the skin-crawl music with the treble violins, and a video of swarming bugs.)
And it is happening right out in the open.
The Culture
If you’re wondering how on earth OpenAI and others could be so brazen, the explanation is simple. Silicon Valley has created a culture where anyone who is not them… anyone who is not seeking to break things… or make a quick billion… is a sucker.
Eric Schmidt, former Google CEO and Valley veteran, recently visited Stanford University. He instructed the assembled students to use AI to make a copy of TikTok, and to try and publish their own version.
He said, “What you would do if you're a Silicon Valley entrepreneur, which hopefully all of you will be, is if it [your copied version of Tik Tok] took off [as a successful service]...
“…then you'd hire a whole bunch of lawyers to go clean the mess up, right? But if nobody uses your product, it doesn't matter that you stole all the content.”
Steal first, pay later.
Just what OpenAI is doing.
Actually the formula is: steal first, and if you get caught, pay later.
After making these remarks, Schmidt said, “And do not quote me.”
Someone had to add, “You’re on camera.”
I love that. You’re on camera. It’s like, whoops. But there’s something about the scene that’s so disturbing. It’s a window into intimacy. The old lion, speaking to youth. Sharing, authentically, his life’s lessons. Which seem to be: Steal from other people. It’s so easy to do. And so hard to get caught. And when you do get caught, only the really smart ones will complain. And there are not many of those. And when they do, you’ll be so rich, you can just pay off the smart ones, and the rest will let you get away with it.
Some speech to the graduates. Let’s try a different version.
What It Means to You
Value what you have. The good news is, your intellectual property is valuable. It should make you feel rich to have Sam Altman want to steal from you. The Times realized their journalism was a critical part of ChatGPT. Guess quality journalism matters.
Your intellectual property matters, too. There’s something poignant about the concept of Common Crawl. Less as an open storage locker for IP thieves. More as a hangar for the advancements in our civilization. When you think sweepingly about the human advance of knowledge, of consciousness, of skills… it seems so vague. But when you scoop it up in a big fat database…well, then it’s queryable. And fairly concrete. You can see how far we’ve come. And our progress comes from incremental steps: one article or scientific study at a time, contributed by someone with domain expertise, who put in the hours to research, write, and document.
So don’t give it away. Either as a writer and researcher, check your settings. Make sure you contribute to the LLMs as little as you can.
Secure the perimeter. There are technical experts trying to take your data. Consult your own experts to defend it, and keep in mind that the game changes. Trends in AI are pointed towards local processing (see federated learning, or Apple’s edge AI strategy) and small models trained on specific, proprietary data sets--as a means to leverage the LLMs while keeping intellectual property safe.
In the meantime, DataStory subscribers, if you have a pulse, and a heart, you may steal this blog.
That excludes the bots. And—sounds like—Eric Schmidt.